Documentazione di JSesh
Modifiche ai font
Il problema delle modifiche ai font
Quasi ogni versione di JSesh apporta modifiche ai font. In molti casi, aggiungo nuovi simboli, che probabilmente non daranno fastidio alla maggior parte degli utenti. Cerco di documentare questi simboli, quindi consultate la sezione Descrizione del simbolo nella palette dei simboli.
Tuttavia, potrò anche alcuni simboli esistenti. Potrebbe essere per motivi scientifici, se il simbolo fosse palesemente sbagliato, o se volessi avvicinarmi di più a Hieroglyphica e correggere un dettaglio o due. Troverete molti esempi nella versione di JSesh 7.9 che ha seguito le osservazioni inviatemi dal Dr. Peter Dils. Contiene modifiche minori, come una leggera modifica allo strumento di scrittura visualizzato dal segno B8G B8G, e modifiche più significative come la corona del segno A302A A302A.
Posso anche modificare un segno per motivi puramente estetici. Ad esempio, ho ridotto la larghezza delle linee del segno H8 H8, che risaltava troppo. Intendo anche modificare un giorno il segno G37. La versione attuale è perfettamente valida e ha le fonti; l'ho disegnata da un glifo nella sala ipostila di Karnak; ma non si adatta allo stile più dettagliato dei segni disegnati dal Sig. Serge THOMAS.
Il problema è che la maggior parte degli utenti copia/incolla la grafica JSesh nei propri documenti. Se sei nel bel mezzo della redazione di un articolo, un libro o una tesi di dottorato e modifichi la versione di JSesh, potresti ritrovarti con parti del documento che utilizzano la vecchia versione del font e altre parti che utilizzano il nuovo font, il che potrebbe essere fastidioso. Il lettore potrebbe persino chiedersi se le differenze siano state codificate di proposito. Cosa puoi fare?
La/le soluzione/i
Non fare (quasi) nulla
Le prime soluzioni sono molto semplici:
- la prima possibilità è non aggiornare JSesh. È semplice e segue la regola, se non è rotto, non aggiustarlo.
- la seconda soluzione è mantenere entrambe le versioni di JSesh. Ho deciso di usare una cartella diversa per ogni installazione di JSesh. In questo modo, se lo desiderate, potrete avere una raccolta completa di versioni di JSesh.
Gestiscilo a livello di font
Come sapete, potete avere una cartella personalizzata per i vostri geroglifici. Potete semplicemente ottenere i segni dalla versione A di JSesh e copiarli in una cartella per utilizzarli nella versione B di JSesh.
Ci sono due modi per farlo.
Approccio con catalogo
Il sito web di JSesh ora offre una sezione che elenca le differenze di segno tra le versioni di JSesh.
Ogni pagina di questa sezione è dedicata a un aggiornamento di JSesh dalla versione n-1 alla versione n (beh, i numeri di versione non sono così semplici, ma si tratta di una versione alla successiva).
Nella parte superiore della pagina, si trovano due link:
- Tutti i segni rilevanti nella versione-(n-1)
- Tutti i segni rilevanti nella versione-n
Ogni link consente di recuperare un file ZIP contenente i segni specifici della versione corrispondente. È possibile decomprimerlo e copiarne il contenuto nella cartella dei glifi.
È utile per passare dalla versione n alla versione n-1 (o viceversa).
È presente anche un elenco delle modifiche a livello di glifo, con eventuale spiegazione, e la possibilità di recuperare il glifo. Ogni disegno è un collegamento che porta al file SVG del glifo.
Approccio tecnico
Per prima cosa, devi installare entrambe le versioni di JSesh. Poi, nella "vecchia" versione, cerca un file chiamato jseshGlyphs-(NUMERO VERSIONE).jar. Contiene i glifi di questa versione di JSesh. Copialo, rinominalo in jseshGlyphs-(NUMERO VERSIONE).zip e decomprimilo. Troverai i glifi come file SVG in una cartella. Seleziona semplicemente questa cartella come cartella personale dei glifi e, voilà, tornerai a questa versione di JSesh per quanto riguarda i font.
I nuovi simboli sono un problema?
A prima vista, un font con un nuovo simbolo non è un problema... tuttavia, non è così semplice, soprattutto se si ha a che fare con database di testo.
Ad esempio, osservando le paleografie, ho notato che nella maggior parte dei casi il segno E1, quando significa bestiame ꞽḥ.w, mnmn.t..., presenta corna a forma di lira. È piuttosto ben documentato. Gardiner ha scelto di avere un segno E1 più generico, che può essere utilizzato anche per il toro, kꜣ.
In una modifica di JSesh 7.9, intendo proporre:
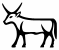 la "vecchia" versione del segno, che corrisponde alla forma di Gardiner (forse con corna leggermente più corte);
la "vecchia" versione del segno, che corrisponde alla forma di Gardiner (forse con corna leggermente più corte);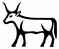 la versione con corna a forma di lira, più comune nelle liste di offerte.
la versione con corna a forma di lira, più comune nelle liste di offerte.
Il problema nell'aggiungere una nuova variante di un segno è il seguente: i testi già codificati, e il cui originale potrebbe contenere la nuova variante, utilizzano il vecchio codice. Questo non li rende illeggibili o errati isolatamente, ma se si vogliono calcolare delle statistiche, ad esempio, non si troveranno tutte le occorrenze *reali* del segno.
Detto questo, temo che creare un ampio database di testi, accurato a livello di segno, sia quasi impossibile, a causa del fattore umano. Richiederebbe una disciplina di codifica e correzione di bozze molto rigorosa.
Allo stesso tempo, vorrei sbagliarmi e sogno un sistema che possa dire quando una particolare variante di un segno è attestata.